Ordering a revision of a power electronics board from Aisler I decided to get a
metal paste stencil as well to be able to cleanly solder using the reflow oven.
I already did a first board just taping the board and stencil to the table and applying solder paste. This
worked but it is not very handy.
Then I came with the idea to use a 3D printed PCB holder that would ease the process.
The holder
The holder (just a rectangle with a hole) tightly fits the PCB. It is a bit larger then the stencil and 0.1mm less thick then the PCB
to make sure the connection between the PCB and the stencil is tight.
I first made some smaller test prints but after 3 revisions the following openSCAD script gave a perfectly
fitting PCB holder:
// PCB size
bx = 41;
by = 11.5;
bz = 1.6;
// stencil size (with some margin for tape)
sx = 100; // from 84.5
sy = 120; // from 104
// aisler compensation
board_adj_x = 0.3;
board_adj_y = 0.3;
// 3D printer compensation
printer_adj_x = 0.1;
printer_adj_y = 0.1;
x = bx + board_adj_x + printer_adj_x;
y = by + board_adj_y + printer_adj_y;
z = bz - 0.1; // have PCB be ever so slightly higher
difference() {
cube([sx,sy,z], center=true);
cube([x,y,z*2], center=true);
}
Assembly
The PCB in the holder:

The stencil taped to it:

Paste on stencil:

Paste applied:

Stencil removed:

Components placed:

Reflowed in the oven:

Conclusion
Using the 3D printed jig worked good. The board under test:

I'm taking a brief look at cheap quality PCB providers oshpark, aisler and JLCPCB.

PCB quality
All 3 provide nice quality good looking PCBs. (Click on a picture to see the full scale photo)
oshpark

As always in beautiful OshPark Purple. Only small downside compared to others is the rough breakoffs.
aisler

Looks great.
jlcpcb

Looks great as well. No gold but it still soldered great. A bit sad they include a production code on the silk screen,
which could be a problem for PCBs that are visible.
Ease of Order
oshpark
Just upload the .kicad_pcb file, very convenient. Shows a drawing of how your board will look.
aisler
Same, just upload the .kicad_pcb file and shows a drawing. Option to get a stencil.
jlcpcb
Upload gerbers and shows a drawing. Option to get a stencil.
Price
This is where it gets a bit more tricky to compare ;)
oshpark
3 boards
$1.55 shipped, as cheap as it gets for a 20 x 10 mm board.
aisler
3 boards
5.70 Euro shipped, still a good price.
jlcpcb
This is of course a bigger board (the other two were the same).
10 boards
$2 + $5.7 shipping gives $7.7.
Delivery
oshpark
- ordered: April 30th 2018
- shipped: May 8th 2018 (from USA)
- arrived: May 15th 2018 (in Belgium)
Took 15 days from order to arrival.
aisler
- ordered: April 30th 2018
- shipped: May 9th 2018 (from Germany)
- arrived: May 11th 2018 (in Belgium)
Took 11 days from order to arrival.
jlcpcb
- ordered: May 5th 2018
- shipped: May 7th 2018 (from Singapore)
- arrived: May 18th 2018 (in Belgium)
Took 13 days from order to arrival.
Conclusion
All three show an impressively fast delivery and a good quality board.
Oshpark is still the king of cheap for tiny boards.
JLCpcb gives you 10 boards, and could be cheaper for bigger boards.
Aisler is the fastest, but only marginally.
Both Aisler and JLC have an option for a stencil which is interesting.
I'll be using all of them depending on the situation (need for stencil, quantity, board size, rush shipping, ...)
History
Back in Februari 2013 then coworker Romain S. showed me the new trend of programming editors
that do continuous compilation while you type, showing you immediate feedback on your code.
In parallel I also worked on 3D modeling for my 3D printer using the OpenSCAD program.
OpenSCAD works by writing code in its custom language and then have it rendered.
An example:
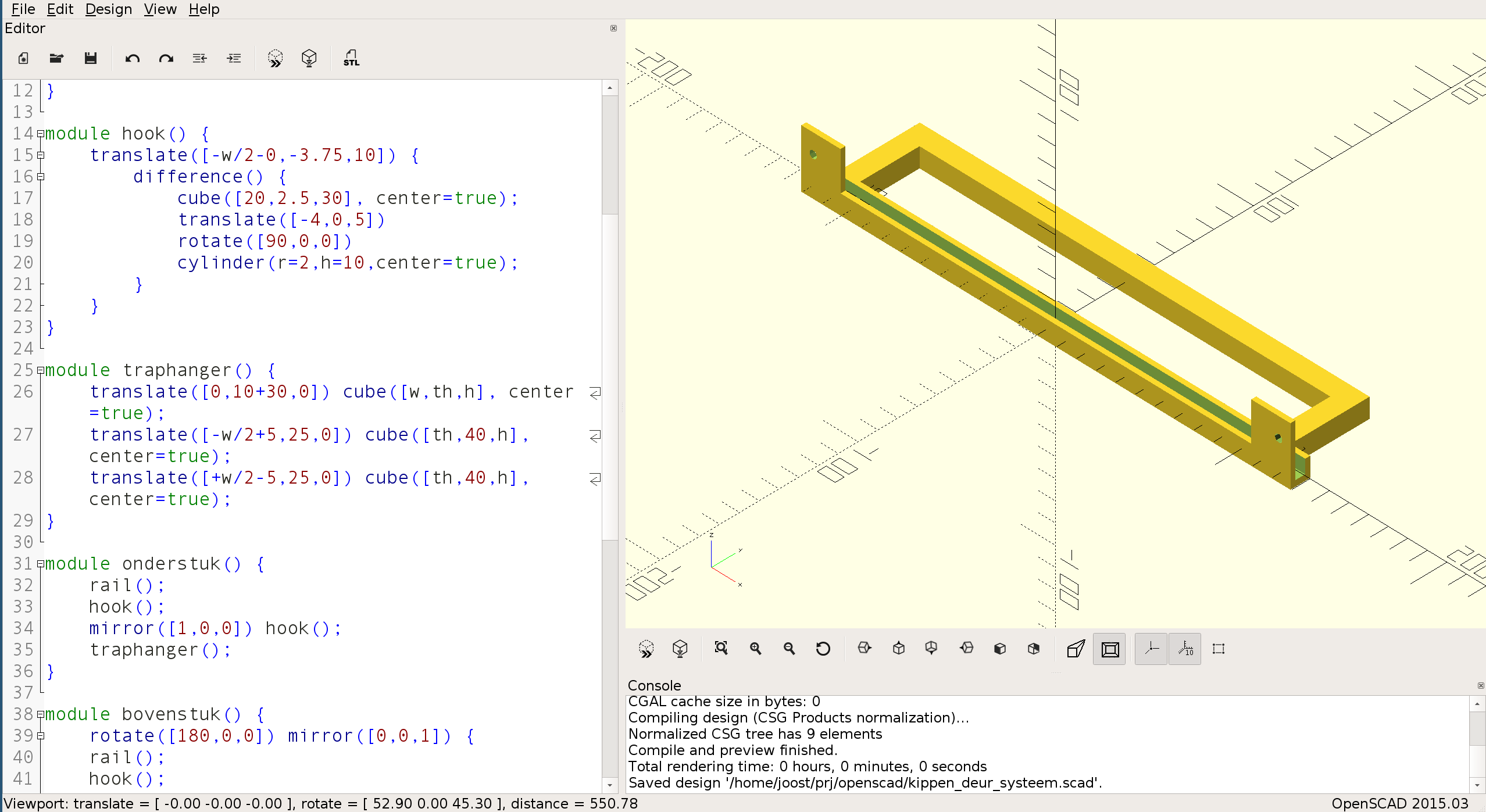
I had this idea of combining these two approaches to make an electronics footprint generator. And so the
development of the original madparts program started.
To go quick I decided to write the program in python, but I wanted a compact language for the footprints so
there I decided to use coffeescript, a functional javascript like language that compiles to javascript.
Also I used openGL shading language for most of the drawing,
because I found it interesting and hadn't touched it before.
Several changes were made among the way, and end of March 2013 a first release was made. It supported both Kicad and Eagle and linux, mac and windows.
After this a command line version of the program was added, and Debian packaging and 1.1 was released in May 2013.
In August 2013 1.2 was released which added support for the then brand new symbolic expressions based file format in Kicad.
In August 2015 the 2.0 release was done with mostly bugfixes and an update to the file format, but it also completely removed
the whole file management system which existed, simplifying the program to just work on one file.
At this point the program pretty much did all I needed so further development stalled except for some minor bugfixes.
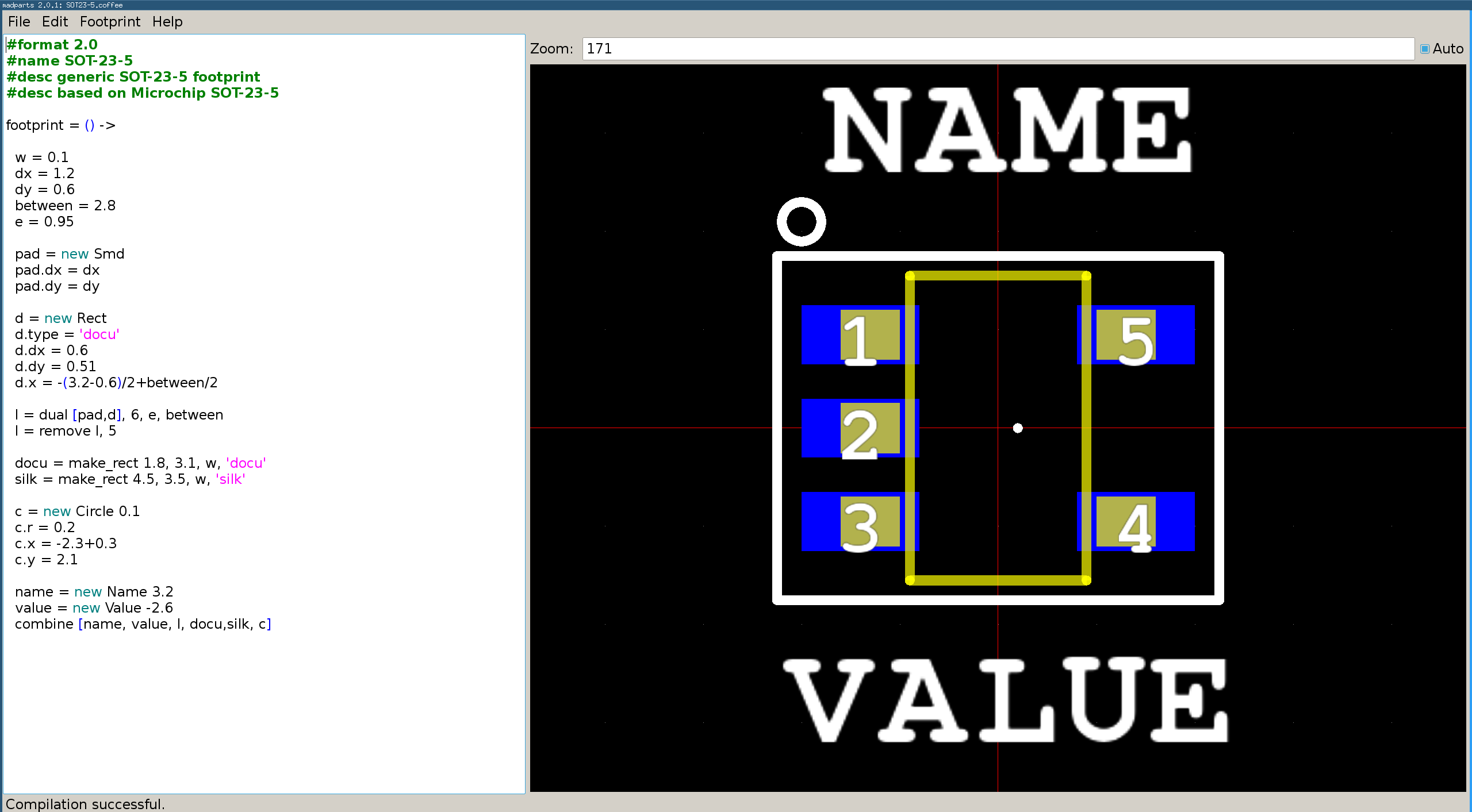
Rust rewrite
In August 2016 I had been playing with the then pretty new rust programming language and decided
a rewrite in it and simplifying the program even further would be fun to do.
The following were my initial goals:
- ditch the editor, and support any external editor
- use python instead of coffeescript
- introduce KLC (Kicad Library Convention) checking
- only support kicad export
Some brief searching showed that Qt (which I used in the python version) support was limited at best but GTK+ and cairo support seemed quite
good with reasonable APIs (gtk-rs), and python support seemed to be ok with PyO3.
Practical
file monitoring
By monitoring the file being edited by an external editor via inotify the program can see when
a change is saved and render the file. There is a practical caveat there though: most editors actually write the content to a temporary
file and move that file over the old file on save (to avoid loss on case of system crash or power loss). This means in practice instead of
monitoring the file, you have to monitor the containing directory.
let _file_watch = ino.add_watch(
&filedir,
WatchMask::CREATE | WatchMask::MOVED_TO | WatchMask::CLOSE_WRITE,
).unwrap();
python interfacing
Using PyO3 running a python interpreter inside of rust is pretty straightforward. The biggest issue I ran into was dealing with the error situations:
- the python file is invalid python (compile time error)
- the python file fails to run (runtime error)
While it is possible to get errors out of python into rust this is tedious and verbose.
After some testing I came with a simple solution: do it all in python, providing python the filename to process, and when it fails,
capture this in python as well and convert it in a simple Error object meaning from the rust perspective the python code always succeeds,
it just has to check for this error object and display then contained message it when it is there instead of drawing the footprint.
def handle_load_python(filename):
try:
exec(open(filename).read(), globals(), globals())
return flatten(footprint())
except:
import sys, traceback
exc_type, exc_value, exc_traceback = sys.exc_info()
message = "".join(traceback.format_exception(exc_type, exc_value, exc_traceback))
e = PythonError(message)
return [e]
rendering
Using Cairo rendering is pretty straightforward as well. A few traits on the Element type make it work:
trait BoundingBox {
fn bounding_box(&self) -> Bound;
}
pub trait DrawElement {
fn draw_element(&self, &cairo::Context, layer: Layer);
}
BoundingBox calculates the Bound of an element. By knowing all the bounds and combining them the program can automatically scale the drawing canvas correctly.
DrawElement allows an element to draws on a certain Layer. This is called Layer by layer for each element to have proper z-axis stacking of the drawings.
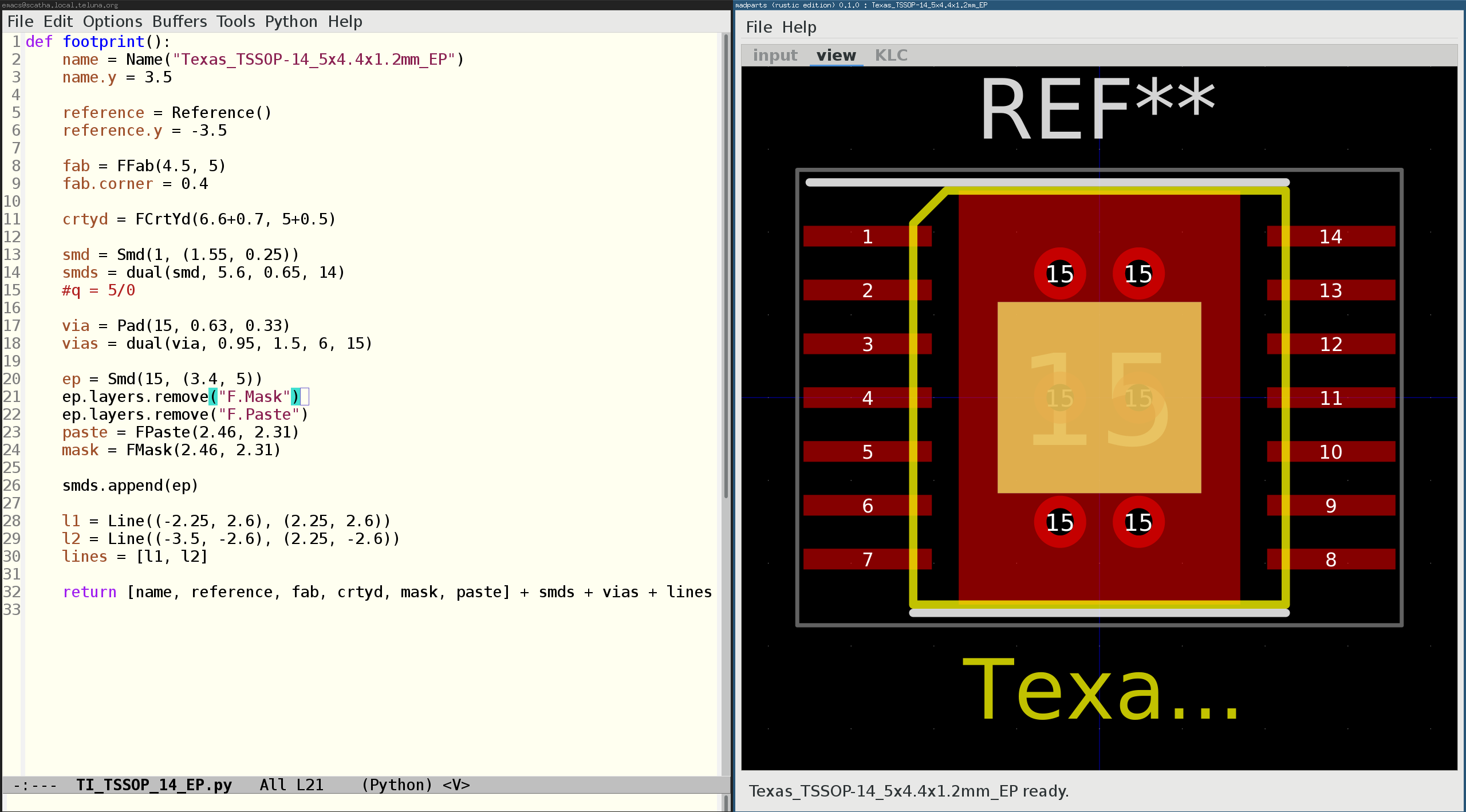
KLC
KLC is supported by just executing the python KLC tool check_kicad_mod.py. The result is displayed in the KLC tab.
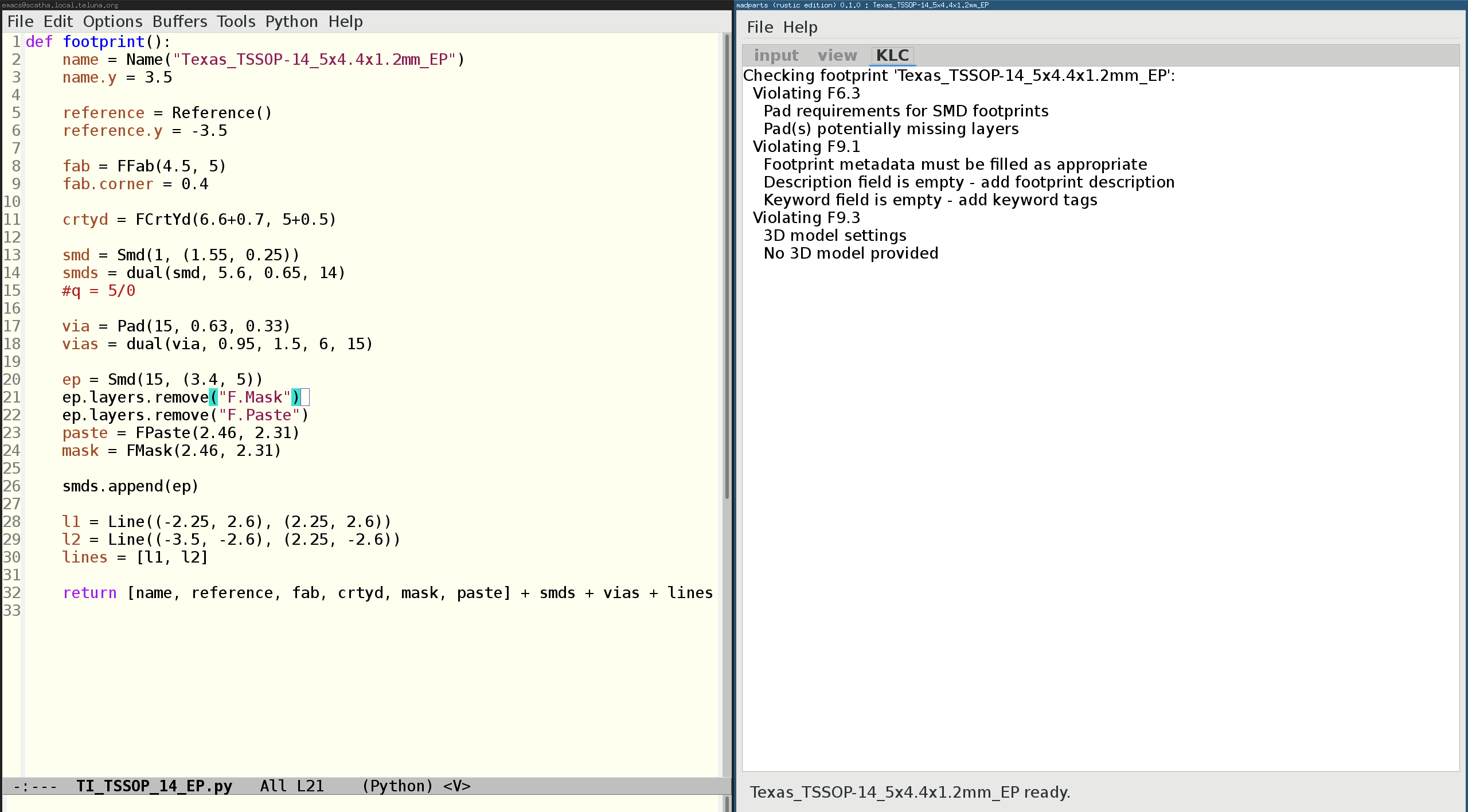
exporting
Exporting just saves the footprint as a .kicad_mod file for usage in Kicad.
Release
This is the release 1.0 and the first public release. This means the program works, but is still far from feature complete.
I'm adding more features as I need them for footprints.
Documentation is not available yet, but I suggest looking at the examples in the footprint/ subdirectory or look in src/prelude.py directly to
see what is supported by the python format.
For now the program is only tested in Linux but it should also run with perhaps minimal changes on OSX or Windows.
I'm always happy to get a pull request for that on github.
Further plans
More features will be added as needed.
Other things planned:
- command line direct conversion option for scripting/building
- possibility for having arguments for the footprint() function to allow for generating of collections of footprints with one script
(this blog post was originally posted at rustit.be)
Problem
I have the following sql table:
CREATE TABLE system (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL UNIQUE,
allegiance_id SERIAL REFERENCES allegiance (id),
state_id SERIAL REFERENCES state (id),
government_id SERIAL REFERENCES government (id),
security_id SERIAL REFERENCES security (id),
needs_permit BOOLEAN DEFAULT FALSE,
power_state_id SERIAL REFERENCES power_state (id),
x DOUBLE PRECISION NOT NULL,
y DOUBLE PRECISION NOT NULL,
z DOUBLE PRECISION NOT NULL,
simbad_ref VARCHAR DEFAULT '',
controlling_minor_faction_id SERIAL, -- TODO REF
reserve_type_id SERIAL REFERENCES reserve_type (id),
is_populated BOOLEAN DEFAULT FALSE,
edsm_id SERIAL,
updated_at TIMESTAMPTZ
);
Running diesel print-schema > src/schema.rs generates the following schema code:
table! {
system (id) {
id -> Int4,
name -> Varchar,
allegiance_id -> Int4,
state_id -> Int4,
government_id -> Int4,
security_id -> Int4,
needs_permit -> Nullable<Bool>,
power_state_id -> Int4,
x -> Float8,
y -> Float8,
z -> Float8,
simbad_ref -> Nullable<Varchar>,
controlling_minor_faction_id -> Int4,
reserve_type_id -> Int4,
is_populated -> Nullable<Bool>,
edsm_id -> Int4,
updated_at -> Nullable<Timestamptz>,
}
}
Compiling this gives the following error among things:
error[E0277]: the trait bound `(schema::system::columns::id, schema::system::columns::name, schema::system::columns::allegiance_id, schema::system::columns::state_id, schema::system::columns::government_id, schema::system::columns::security_id, schema::system::columns::needs_permit, schema::system::columns::power_state_id, schema::system::columns::x, schema::system::columns::y, schema::system::columns::z, schema::system::columns::simbad_ref, schema::system::columns::controlling_minor_faction_id, schema::system::columns::reserve_type_id, schema::system::columns::is_populated, schema::system::columns::edsm_id, schema::system::columns::updated_at): diesel::Expression` is not satisfied
--> src/schema.rs:58:1
|
58 | / table! {
59 | | system (id) {
60 | | id -> Int4,
61 | | name -> Varchar,
... |
77 | | }
78 | | }
This is a bit unclear and I first thought that perhaps there is an issue with the Timestamptz type as commenting out that field makes it compiles fine. However further testing showed that commenting out any field solves it.
Solution
diesel has a default table column limit of 16. Our table has 17 columns. Adding large-tables to Cargo.toml solves it.
[dependencies]
diesel = { version = "1.0", features = ["postgres", "chrono", "large-tables"] }
Thinking about it this way the error actually makes sense. Diesel has no implementation for diesel::Expression for a 17 column table (which is implemented as a 17 size tuple).
(this was first posted on rustit.be)
Intro
For a program I'm working on I have this datastructure:
pub enum State {
None,
Expansion,
War,
CivilWar,
...
}
This same datastructure is returned from different external JSON API's where the formatting is slightly different.
I'm using serde and serde_json for deserialization.
Without any special processing the following program will deserialize "CivilWar" to State::CivilWar:
#[macro_use]
extern crate serde_derive;
extern crate serde_json;
#[derive(Debug, Deserialize)]
pub enum State {
None,
Expansion,
War,
CivilWar,
...
}
fn main() {
let s = r#" "CivilWar" "#;
let c:State = serde_json::from_str(s).unwrap();
println!("input: {} output: State::{:?}", s, c);
}
This will output: input: "CivilWar" output: State::CivilWar.
Lowercase
The JSON format I'm deserialiazing from actually specifies the state as lowercase. This is easily accomodated by adding an annotation #[serde(rename_all = "lowercase")] to the enum:
#[derive(Debug, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum State {
None,
Expansion,
War,
CivilWar,
...
}
Now "civilwar" will be deserialized as State::CivilWar. Of course "CivilWar" won't deserialize anymore.
Space
However some files contain "civil war" with a space in between. This will still not be mapped correctly. As we have multiple possible inputs, a simple rename will no longer suffice.
A custom implementation of Deserialize works, but is a lot of boilerplate code:
#[derive(Debug)]
pub enum State {
None,
Expansion,
War,
CivilWar,
...
}
impl<'de> Deserialize<'de> for State {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
let s = String::deserialize(deserializer)?.to_lowercase();
let state = match s.as_str() {
"none" => State::None,
"expansion" => State::Expansion,
"war" => State::War,
"civil war" | "civilwar" => State::CivilWar,
...
other => { return Err(de::Error::custom(format!("Invalid state '{}'", other))); },
};
Ok(state)
}
}
Variant deserialize_with
In principle it should be possible to make a custom deserialization function only for the offending variants (State::CivilWar and State::CivilUnrest) by introducing a variant annotation like this:
#[derive(Debug, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum State {
None,
Expansion,
War,
#[serde(deserialize_with = "de_civilwar")]
CivilWar,
Election,
Boom,
Bust,
CivilUnrest,
Famine,
Outbreak,
Lockdown,
Investment,
Retreat,
}
fn de_civilwar<'de, D>(deserializer:D)-> Result<(), D::Error>
where D: Deserializer<'de> {
let s = String::deserialize(deserializer)?.to_lowercase();
println!("found: {}", s);
if s.as_str() == "civilwar" || s.as_str() == "civil war" {
Ok(())
} else {
Err(
de::Error::invalid_value(
Unexpected::Str(&s),
&r#""civil war" or "civilwar""#
)
)
}
}
However using this fails with an error: invalid type: unit variant, expected newtype variant.
At this point it is unclear to my why this doesn't work as it matches the documentation.
To narrow it down I implemented a variant of the problem based on the test contained in serde:
#[macro_use]
extern crate serde_derive;
extern crate serde_json;
extern crate serde;
use serde::de::{self, Deserialize, Deserializer, Unexpected};
#[derive(Debug, PartialEq, Serialize, Deserialize)]
enum WithVariant {
#[serde(deserialize_with = "deserialize_u8_as_unit_variant")]
Unit,
}
fn deserialize_u8_as_unit_variant<'de, D>(deserializer: D) -> Result<(), D::Error>
where
D: Deserializer<'de>,
{
let n = u8::deserialize(deserializer)?;
if n == 0 {
Ok(())
} else {
Err(de::Error::invalid_value(Unexpected::Unsigned(n as u64), &"0"))
}
}
fn main() {
let s1 = "0";
let i:u8 = serde_json::from_str(s1).unwrap();
println!("i: {}", i);
let s = "0";
let c:WithVariant = serde_json::from_str(s).unwrap();
println!("input: {} output: {:?}", s, c);
}
This fails in a different way, with the error: ExpectedSomeValue, line: 1, column: 1.
Either I'm overlooking something or there is a bug in the libraries.
Update
After some help from David Tolnay, one of authors of serde,
it turns out that the enum variant deserialize_with feature is meant to be used in a different way.
For the example above from the testcase this works:
let s = r#"{ "Unit": 0 }"#;
let c:WithVariant = serde_json::from_str(s).unwrap();
println!("input: {} output: {:?}", s, c);
meaning the variant needs to be contained in another structure.
Finally David offered the following elegant alternative:
use serde::de::{Deserialize, Deserializer, IntoDeserializer};
#[derive(Debug, Deserialize)]
#[serde(rename_all = "lowercase")]
#[serde(remote = "State")]
pub enum State {
Expansion,
CivilWar,
/* ... */
}
impl<'de> Deserialize<'de> for State {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where D: Deserializer<'de>
{
let s = String::deserialize(deserializer)?;
if s == "civil war" {
Ok(State::CivilWar)
} else {
State::deserialize(s.into_deserializer())
}
}
}
which provides the special handling but avoids the boilerplate for the common cases.
All the example code used in this blog past can be found here.
(this was first posted on rustit.be)


